Editor’s Note: Anton Mikanovich of Promwad describes how to use a fast path implementation of the Linux OS to boost performance of a Small Office/Home Office traffic router design, using Marvell’s new ARMv5TE-based Kirkwood processor.
High-speed data transfer networks ubiquitous in today’s world. We use them while working on the computer, making phone calls, watching digital TV, receiving money from an ATM machine, and in any situation where we need to transfer digital information. The greater the volume of information and the number of its recipients, the more stringent are the speed and throughput requirements.
The defacto standard for data transfer in most computer networks is Ethernet and TCP/IP. These protocols allow for different topologies dividing large initial networks into subnets using routers. The simplest way of building a network is shown in Figure 1:
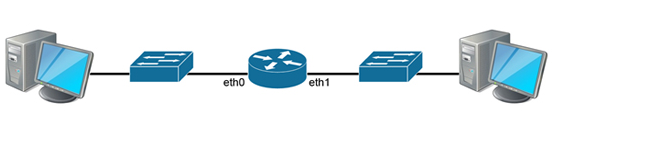
Figure 1. A basic network with a router
When transferring information flow Computer A to Computer B, the traffic in packets comes to the router interface eth0, which forwards the packet to the operating system where it passes through different levels of the TCP/IP protocol stack and is decrypted to determine the future path of the packet. After receiving the destination address and determining the redirection rules, the operating system packs the packet again, depending on the protocol used, and puts it out via the eth1 interface.
Only some of the header fields change; the bulk of the package remains the same. The faster the packet goes through all these stages, the greater capacity the router can achieve. While the problem of enhancing router performance was not a big issue when networks had a capacity of 100 Mbit/s, with the advent of gigabit speeds there is a need to improve the efficiency of equipment.
It is easy to see that this thorough traffic processing is redundant for most packets of known types. By sifting and redirecting packets not intended for the device itself at an early stage, you can greatly reduce the traffic processing time. This processing is most often performed before coming to the operating system, which reduces latencies.
This technology minimizes the packet path, hence the name fastpath. Since this acceleration method is based on the low-level part of the network stack and involves information exchange with the network driver, the specific fastpath implementation technology depends on the equipment used.
This article describes how to implement such a scheme using Marvell’s Kirkwood processor architecture, a system-on-chip (SoC) based on the ARMv5TE-compatible Sheeva architecture. Processors based on this architecture are designed specifically for use in network devices such as routers, access points, STB devices, network drives, media servers and plug computers.
The Kirkwood line includes processors with one or two cores and an extensive set of peripherals. Operating frequencies range from 600 MHz to 2 GHz. The entire line has 256 KB L2 cache on board. Older dual-core models also boast FPU.
The basic features of the Marvell Kirkwood processors are given in Table 1 below.
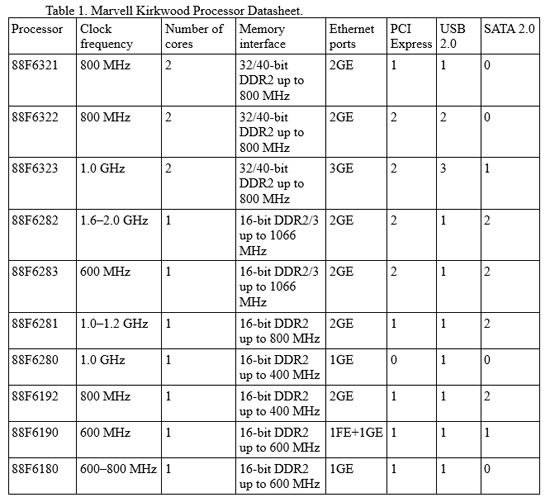
Table 1. Marvell Kirkwood processor datasheet
Network Fast Processing
Since the Kirkwood processor family targets applications that include traffic redirect devices, Marvell also faces the need to implement fastpath in their devices. To solve this problem, engineers have added Network Fast Processing (NFP) to the HAL part of the platform support driver in the Linux 2.6.31.8 kernel.
The relationship between Marvell NFP and other parts of the Linux operating system is shown in Figure 2 below:
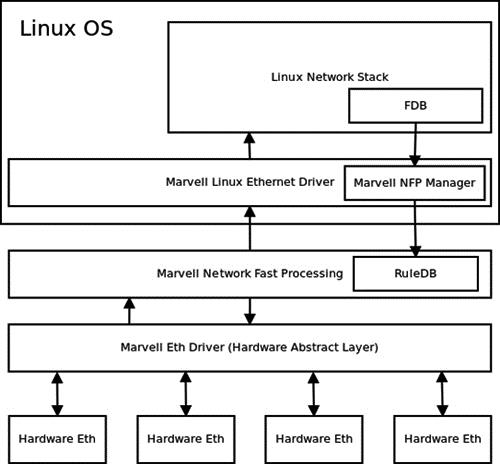
Figure 2: Marvell NFP in the Linux operating system
NFP is implemented as a layer between the gigabit interface driver and the operating system network stack. In short, the basic principle of traffic transfer acceleration is to sift incoming routed traffic packets and output them through the required interface, bypassing the operating system. In addition, the packets not intended for the local interface or that cannot be processed in fastpath are forwarded to the Linux kernel for processing through standard means.
Marvell’s fastpath implementation does not process all possible packet formats, but only the most popular protocols up to the OSI / ISO model transport level. The chain of supported protocols can be roughly presented as follows:
Ethernet (802.3) → [ VLAN (802.1) ] → [ PPPoE ] → IPv4 → [ IPSEC ] → TCP/UDP
Support for higher level protocols is not necessary because this information is not used for routing. Transport protocol header analysis is required for NAT.
A modular structure makes it possible to configure the used parts at the stage of Linux kernel compilation. The following are optional parts:
- FDB_SUPPORT – a hash table of matching MAC addresses and interfaces
- PPP – PPPoE support
- NAT_SUPPORT – IP address translation support
- SEC – IPSec encryption protocol support
- TOS – replacing the type of service field in the IP-header based on the iptables rules
The forwarding database (FDB) is a traffic redirect database located in the Linux kernel. Unlike the routing table, FDB is optimized for quick entry search. Marvell’s fastpath implementation uses its own local ruleDB table in which an entry is added or deleted out of the Linux network stack; the stack code is modified accordingly.
RuleDB for quick search is a hash table with key value pairs, where the value is usually a rule for redirecting a packet with a specific destination address, and the key for fast indexing of this rule is an index generated from the source and destination addresses using a special hash function. The best designed hash function provides the highest chance of matching one index with one rule.
Initially FDB (and, consequently, ruleDB) is empty, which is why every first packet (a packet with no existing FDB entry) goes to the kernel, where a rule is created after processing. After a specified timeout, the entry will be removed from FDB and ruleDB in NFP.
The traffic handling process is as follows:
- The raw data of the packet received is sent to the NFP input.
- If the packet is intended for a multicast MAC address, it is sent to the TCP/IP OS stack.
- If you use FDB and the table does not include an entry for this MAC address, the packet is sent to the OS stack.
- An entry for this MAC address is extracted from FDB. If the address is not marked as local, the system recognizes it as connected in bridge mode and sends the packet through the interface specified in the FDB table entry.
- If the system detects a VLAN or PPPoE header, it discards it and calculates a link to the IP header beginning.
- Labeled fragments of packets are sent to the OS network stack.
- If the package contains ICMP data, the data is forwarded to the OS stack.
- Packets with expired lifetime are sent to the OS stack. Of course, these packets should be discarded, but the TTL expired ICMP reply should be generated using the operating system means.
- The system launches an IPSec header check and begins to process such packets accordingly with a certificate check.
- The system launches a search for the Destination NAT rule to determine the Destination IP address of the packet.
- If a given destination address does not exist, the packet is sent to the network stack. Such packets should also be dropped, but the system should generate the corresponding ICMP response.
- The system launches a search for the Source NAT rule and updates the IP and TCP / UDP header fields according to the DNAT and SNAT rules.
- Based on the routing table, the system calculates an interface through which the packet will be put out.
- If the outgoing interface requires PPP tunneling, the IP packet is wrapped in a PPPoE header, previously reducing TTL and updating the Ethernet header. In this case we cannot calculate the IP packet checksum through hardware means, so we should recalculate the checksum. However, because we know the old checksum and the change in the packet data, we do not have to make all calculations anew, but only adjust the sum by the required amount. If the packet size exceeds the maximum, we forward the packet to the operating system stack.
- In all other cases, the process involves updating the Ethernet header, the checksum, and the type of service field (if necessary and if there is an entry in the ip tables).
- The received Ethernet packet comes out through the required network interface.
Source: Embedded.com